

No dobra, może nie aż tak tajna skoro o niej wiem i mogę tutaj napisać, ale na pewno interesująca. Jeśli lubicie chociaż trochę matematykę, planujecie dokonać jakiegoś oszustwa bazującego na fałszywych danych lub jesteście odpowiedzialni za wykrywanie takich oszustw temat na pewno Was zainteresuje.
Matematyka zawsze była dla mnie lubianą, ale bez przesady, dziedziną wiedzy. Do dziś w wolnym czasie zdarza mi się obejrzeć na youtubie materiał poświęcony jakiemuś ciekawemu zagadnieniu matematycznemu. Byłem jednak mocno zaskoczony, gdy usłyszałem niedawno o prawie Benforda. Samo pojęcie nie było mi wcześniej znane, a reguła, o której mówi spowodowała u mnie chwilę konkretnej zadumy.
Prawo Benforda
Zacznijmy od małego wprowadzenia. Wyobraźcie sobie, że jesteście oszustami (przepraszam, ale to na potrzeby eksperymentu naukowego). Planujecie sfałszować jakieś dane, np. spreparować fałszywe faktury kosztowe albo sfingować wybory. Musicie więc wygenerować pewną ilość danych z większego zbioru. Co istotne, musi to być zbiór obejmujący kilka rzędów wielkości, czyli np. od jeden do jednego miliona, ponieważ tylko w takich zbiorach zauważalne jest prawo Benforda.
Jeśli nie chcecie, aby dane te wyglądały podejrzanie posłużycie się zapewne jakimś systemem, który będzie miał zapewnić ich przypadkowość. Może to być funkcja random w Excelu lub jakiś serwis internetowy typu random.org. Jeżeli coś tam jeszcze pamiętacie z rachunku prawdopodobieństwa to kojarzycie zapewne, że prawdopodobieństwo wylosowania cyfry ze zbioru 0-9 wynosi 1/10 i jest ono równe dla każdej cyfry. Jeżeli zatem otrzymacie zbiór danych (np. kwot na fakturach, głosów przekazanych na danego kandydata w poszczególnych okręgach), w którym liczb zaczynających się na każdą cyfrę będzie mniej więcej tyle samo, uznacie zapewne, że dane wyglądają wiarygodnie. I tutaj niestety pojawia się problem i na scenę wchodzi tajemnicze prawo Benforda.
Natura to nie rachunek prawdopodobieństwa
Okazuje się, że otaczająca nas rzeczywistość wcale nie jest tak przypadkowa. Występujące w realnym świecie wielkości liczbowe podlegają pewnej tajemniczej regule. Otóż jeśli weźmiemy zbiór danych reprezentujący jakieś rzeczywiste wielkości, to zachodzi w nim następująca prawidłowość:
- liczby zaczynające się od 1 stanowią 30,1% wszystkich liczb
- liczby zaczynające się od 2 stanowią 17,6% wszystkich liczb
- liczby zaczynające się od 3 stanowią 12,5% wszystkich liczb
- liczby zaczynające się od 4 stanowią 9,7% wszystkich liczb
- liczby zaczynające się od 5 stanowią 7,9% wszystkich liczb
- liczby zaczynające się od 6 stanowią 6,7% wszystkich liczb
- liczby zaczynające się od 7 stanowią 5,8% wszystkich liczb
- liczby zaczynające się od 8 stanowią 5,1% wszystkich liczb
- liczby zaczynające się od 9 stanowią 4,6% wszystkich liczb
Czyli bawiąc się w oszustów powinniśmy zadbać o to, aby około 30% spreparowanych danych stanowiły liczby zaczynające się od jedynki, a niecałe 5% liczby zaczynające się od dziewiątki. Są to wartości przybliżone i będą tym dokładniejsze, im większy zbiór danych weźmiemy.
No dobra, ale gdzie konkretnie występuje prawo Benforda?
Praktycznie wszędzie. Regule tej podlegają tak abstrakcyjne i niezwiązane ze sobą dane, jak np.:
- liczby drukowane w gazetach
- ceny towarów w sklepach
- powierzchnie dorzeczy rzek
- ilości mieszkańców w poszczególnych miastach
Nie wierzycie? Weźcie dowolny zestaw danych prezentujący jakieś wartości liczbowe z otaczającego Was świata. Osobiście też nie mogłem w to uwierzyć i zacząłem weryfikować różne zbiory. Poniżej tabela prezentująca liczby wypadków drogowych w Polsce pochodząca ze strony https://statystyka.policja.pl/st/ruch-drogowy/76562,wypadki-drogowe-raporty-roczne.html:
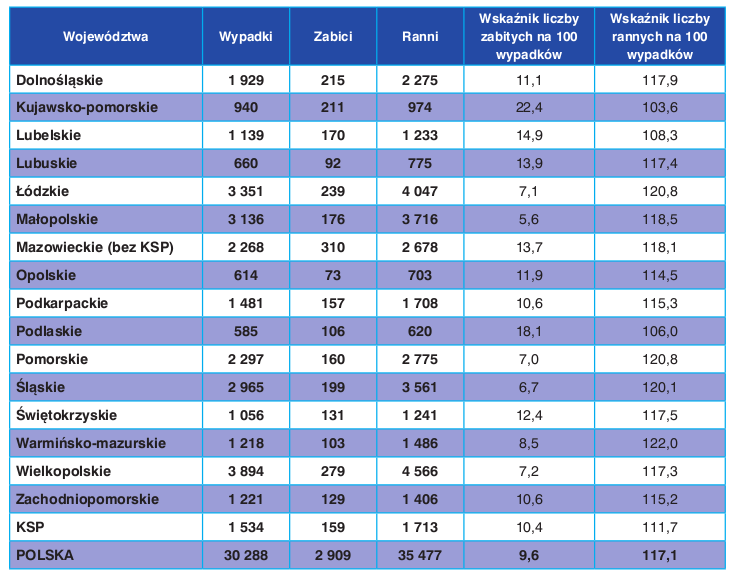
W niewielkich zbiorach danych najwyraźniej będzie widać przewagę liczb zaczynających się od 1 (ok. 30%) i 2 (ok. 18%) oraz znikomą ilość tych zaczynających się od 7, 8 bądź 9 (około 5%). W powyższej tabeli widać to już gołym okiem. Im większy zbiór danych, tym dokładniej wartości pierwszych cyfr będą odpowiadały rozkładowi przedstawionemu w prawie Benforda. W małych zbiorach prawo może natomiast nie zostać zaobserwowane.
Inny przykład – powierzchnie użytków rolnych w poszczególnych krajach Europy wyrażone w hektarach. Dane pochodzą z tej strony GUS:
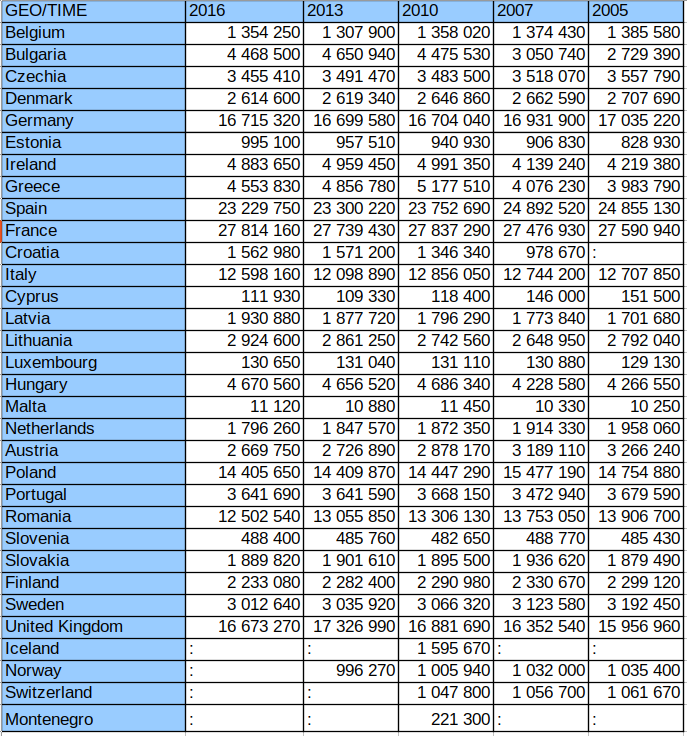
Nadal nie jest to zbyt duży zbiór danych, ale już w powyższej tabeli możemy wyliczyć następującą statystykę:
- 42% liczb zaczyna się od cyfry 1
- 19% liczb zaczyna się od cyfry 2
- 12% liczb zaczyna się od cyfry 3
Polecam Wam poeksperymentować z własnymi zbiorami. Gwarantuję, że im bardziej abstrakcyjne dane będziecie weryfikować tym większe będzie Wasze zdumienie, że to działa. Pamiętajcie, że dokładność będzie tym większa, im większy zbiór danych, a wartości w tym zbiorze konieczne muszą pochodzić z większego przedziału (najlepiej kilka rzędów wielkości).
Prawo Benforda jako narzędzie kontroli
Jak wspomniałem w tytule, prawo Benforda jest stosowane jako narzędzie do wykrywania fałszerstw. Korzystają z niego m.in. urzędy skarbowe (również w Polsce) oraz organy zajmujące się kontrolą wyników wyborów. Oczywiście nie wszystkie odchylenia od rozkładu Benforda muszą od razu świadczyć o nieprawdziwości danych. Do weryfikacji używa się najczęściej cyfr 1 i 2 – liczb zaczynających się od nich powinno być najwięcej oraz cyfr 7, 8 i 9 – liczb zaczynających się od nich powinno być najmniej.
Upewnijcie się więc przed wysłaniem zeznania podatkowego, czy nie ma w nim za mało kratek zawierających na początku cyfrę 1 🙂
Ciekawostka
Chociaż prawo nosi nazwę Benforda, prawidłowość ta została zaobserwowana niezależnie przez Simona Newcomba w 1881 roku oraz Franka Benforda w 1938 roku. Niestety odkrycie tego pierwszego nie spotkało się z większym zainteresowaniem.
Co ciekawe, obaj panowie wpadli na ową prawidłowość w ten sam sposób – posługując się tablicami logarytmicznymi zaobserwowali, iż strony zawierające liczby zaczynające się na cyfry 1, 2 i 3 są dużo bardziej zużyte, co wskazywałoby że występują one w naszym świecie znacznie częściej.
Zostaw e-mail aby otrzymać powiadomienia o nowych wpisach oraz dostęp do materiałów przygotowanych wyłącznie dla subskrybentów.
„Czym… tym…” to niepoprawna forma. Poprawnie jest: „Im…. tym…”.
Dzięki, poprawione.
Ciekawe zjawisko, teraz juz wiem dlaczego od dziecinstwa unikam niskich cyfr w moim algorygmie randomizacji hasel :p jest tez dobre na wszelkie bruteforce’y 🙂 pozdrawiam.
..dając czas na reakcję przy slabych zabezpieczeniach 🙂
Ciężkie życie oszusta. Tyle rzeczy muszą brać pod uwagę, żeby nie dać się wykryć ;p